7.5% accuracy🤫 My Deepwalk with Cartography
For my final CSEP 590C project at UW (I’m finally graduating with my MS degree🎉), I wanted to apply deep learning techniques to an open source project that I maintain: Cartography. Cartography is a Python tool that pulls data on technical assets from multiple sources, like AWS and GCP, and represents them in a Neo4j graph database. Using a graph gives us a map of our infrastructure and this is particularly useful for security and infra teams because you can quickly answer complex questions like “if one of my compute instances gets hacked, what else is immediately at risk?”

This blog post goes over how I found a graph problem to apply deep learning techniques and how at the end I now have more questions than answers. I’ll preface this by first saying that ⚠️I am not a data scientist⚠️ so this post with embarassingly bad results is just me trying to apply ML techniques to a domain that I’m familiar with.
Finding a problem for my solution
(lol)
While brainstorming, my main source of inspiration was Deep Walk: Implementing Graph Embeddings in Neo4j, as well as DeepWalk: Online Learning of Social Representations.
The way I understood it, the DeepWalk technique represents each node in our graph as a vector embedding by taking random walks from each node for a certain number of hops. This is powerful because representing each graph node as a set of numbers potentially gives us a way to quantify how similar nodes are to each other based on their connections.
Embeddings are used in words and sentences in NLP as well, and it was shown in a famous paper that you can calculate the analogy man : woman :: king : queen by performing king - man + woman. I hoped to use vectors in this way with Cartography nodes.
It’s also super cool that @fahadsultan wrote code to make these embeddings in Neo4j, so I wouldn’t even need to work that hard.
My problem: auto-tag AWS S3 buckets
Lyft’s architecture is made up of many many microservices. We use AWS tags to organize assets based on which service they belong to. Not too long ago, I added support in Cartography for AWS Tags. Here’s what tags look like applied to S3 buckets. This lets us quickly find which S3 bucket belongs to which service.
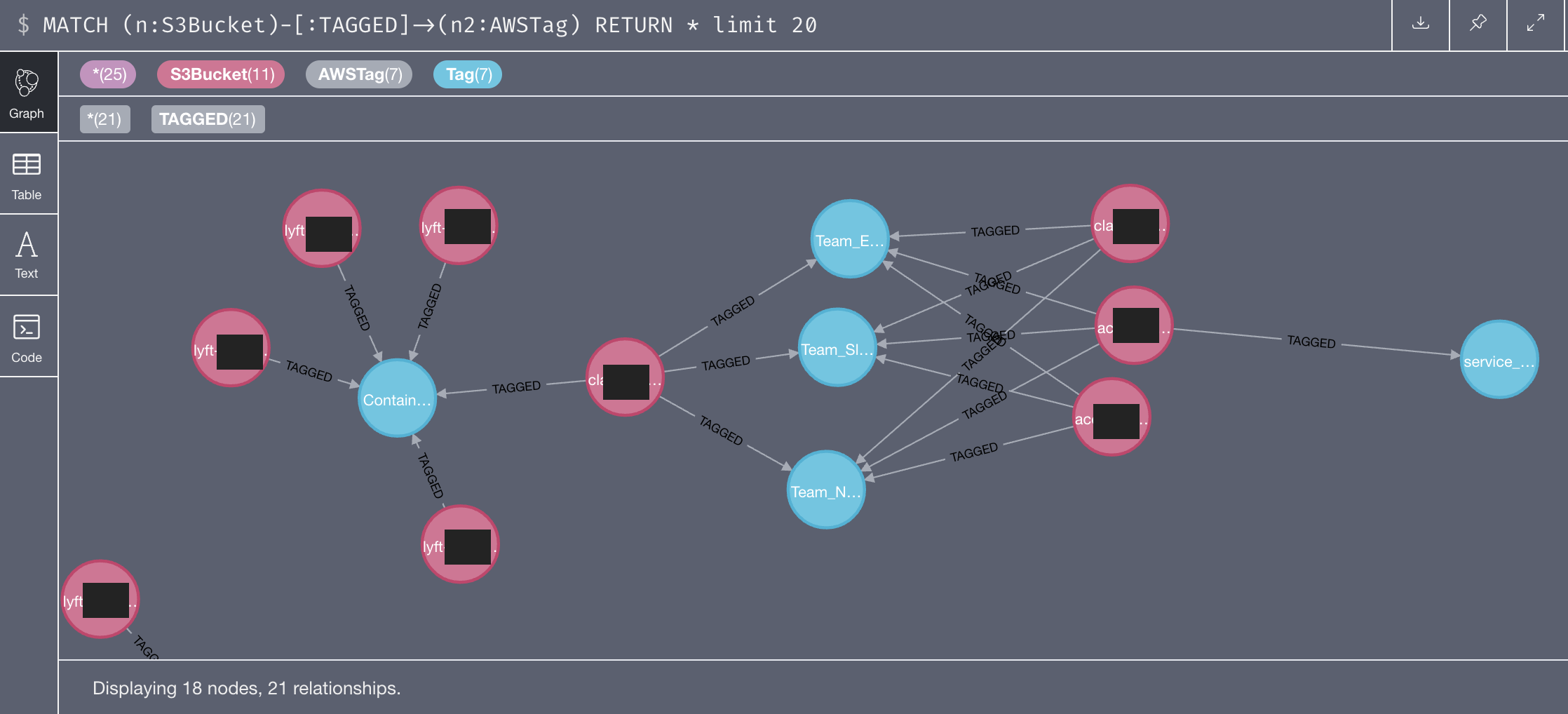
However (and I’m sure almost anyone working in IT can identify), not everything is cataloged or tagged properly and there are many S3 buckets left without tags. It would be really great to have a computer automatically suggest tags for S3 buckets to a reasonable degree of accuracy. My intuition told me this should be possible because S3 buckets can be connected to more node types than just AWS tags and we should be able to infer the tag relationship based on other existing connections. As seen in the Cartography schema,
-
S3Buckets are resources in an AWS Account:
(AWSAccount)-[RESOURCE]->(S3Bucket) -
S3 Access Control Lists apply to S3 buckets:
(S3Acl)-[APPLIES_TO]->(S3Bucket) -
AWS users can read data from S3 buckets:
(AWSPrincipal)-[CAN_READ]->(S3Bucket)
Explained another way, it would be neat to hide the (S3Bucket)-[TAGGED]->(AWSTag) connection from our ML algorithm and see if it can guess the best tag for an S3 bucket based on the other relationships.
My experiment
Setup
I started with a real Neo4j database populated with about 217,000 Cartography nodes and 430,000 edges. Of the nodes, 400 were S3 buckets with AWS service tags connected to them. It looked like this: (S3Bucket{name:"abc"})-[:TAGGED]->(AWSTag{id:"service_name:my_service_name_here"}
Out of these 400 buckets, I deleted their connections to service tags from 80 of them. My idea was to predict tags for these remaining 80 buckets by assigning each of them the tag whose vector was “closest” to them. Explained in slightly more precise terms, my goal was to correctly perform
for bucket in buckets:
bucket.tag = find_closest_tag(bucket)
where
def find_closest_tag(bucket):
min_distance = INF
closest_tag = None
for tag in tags:
dist = distance(embedding(bucket), embedding(tag))
if dist < min_distance:
min_distance = dist
closest_tag = tag
return closest_tag
The glaring assumption here is that the remaining 320 buckets with tags still attached to them fulfill this criteria as well. However at the time of this writing this is the best criteria that I could come up with.
Training the embeddings
First I needed to make embeddings for each node in the graph. Again, lots of thanks to DeepWalkWithNeo. This took almost 12 hours to run on my 2018 Macbook Pro, but this is probably mostly because I ran the Python code as-is without bothering to think about parallelization; oh well.
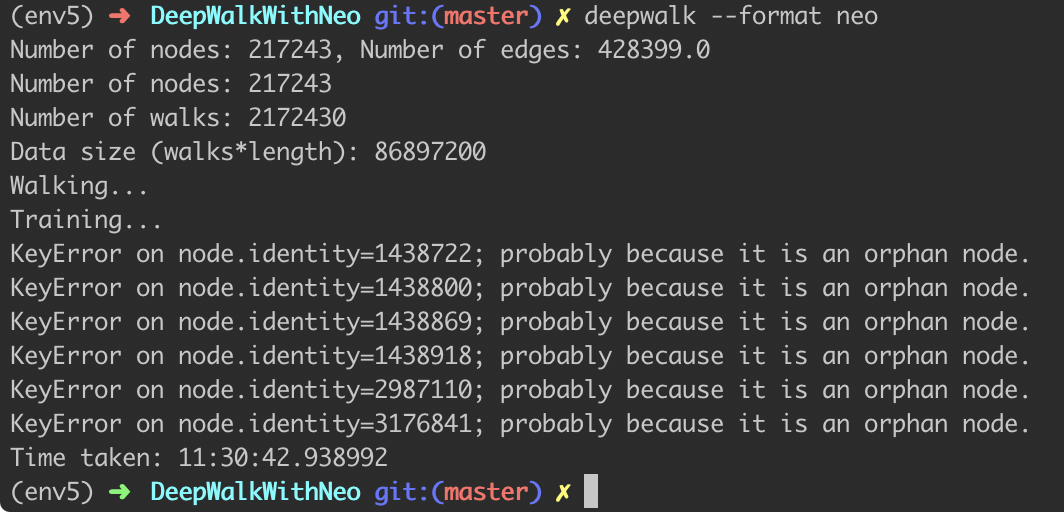
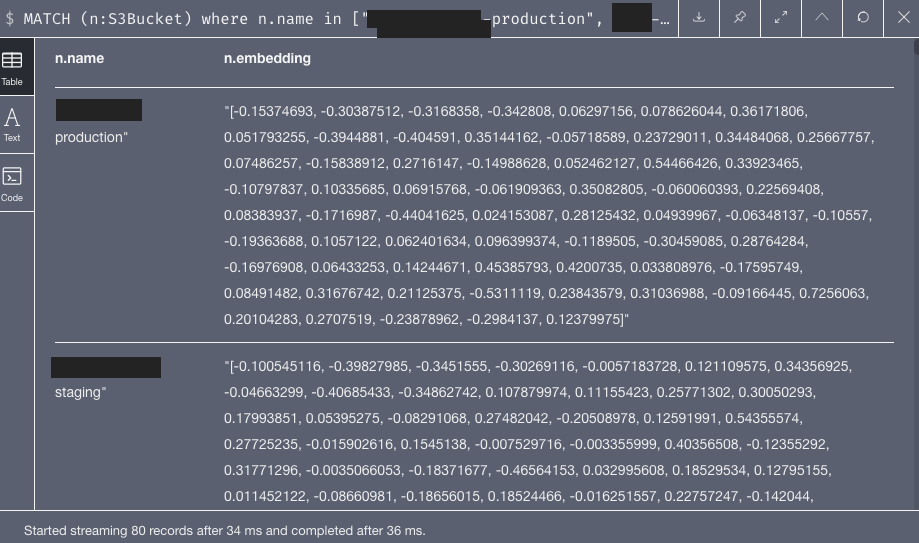
In the end, each node got updated with an embedding field in the graph. You can see this for S3 buckets:
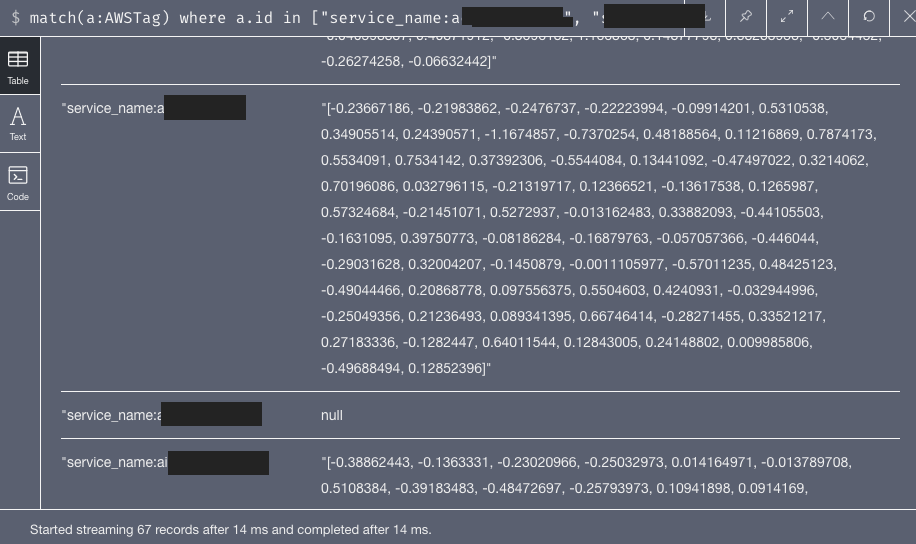
as well as tags:
Evaluation - so did it work?
I was so excited by this point having finally found a pretty neat usecase for using a learning technique for graphs and I was eager to see the results.
I quickly threw together a script to find the closest tag for each bucket and got an accuracy of…
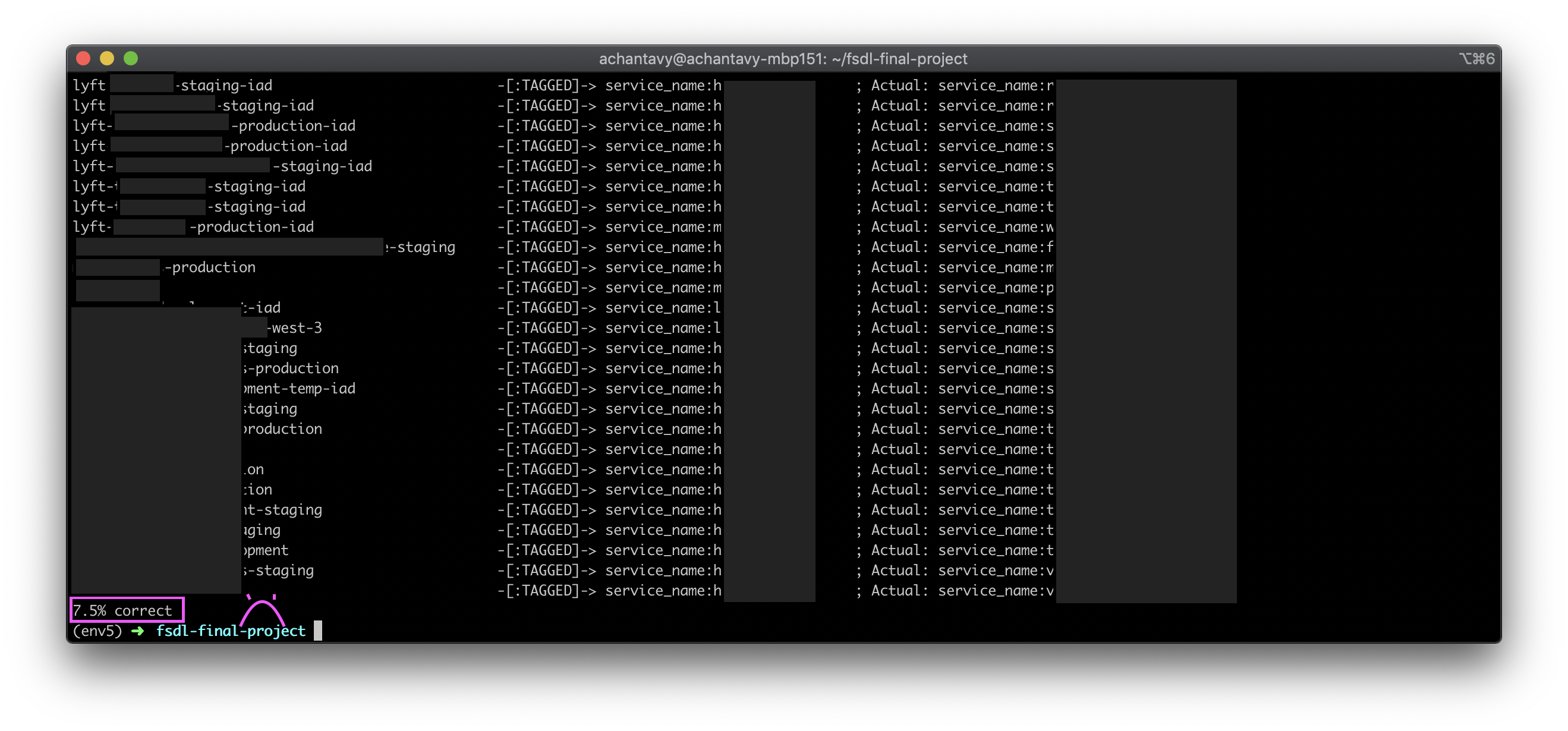
Yup, that’s 7.5% :-(.
Geesh.
What went wrong?!
It looks like many of these buckets are closet to one particular tag but I’m not sure why. I could redesign this calculation so that each bucket gets assigned a unique tag, but I think that’s too strong of an assumption because a tag can be assigned to multiple buckets.
Next steps
If nothing else, this project has given me a lot to think about and work on. I want to try the following ideas:
- Try the reverse direction: for each tag, find the closest bucket.
- Try different embedding techniques, such as those described in this post
- Find a way to reduce the time it takes to build embeddings in this graph (12 hours is awful)
- Try this same experiment but for labels other than S3 buckets. For example maybe I can try to tag EC2 instances instead, or maybe not even deal with tagging at all.
Anyway, I hope you enjoyed this read. If you have any ideas on how I can get better results, please tweet me @alexchantavy. I guess the upside is that with results of 7.5% there is nowhere else to go but up. Do also let me know if you are working on or have solved any other graph-related ML problems! If you’re interested in Cartography, please come say hi in our public Slack as we’d love to hear from you.